Md Akil Raihan Iftee

I am a Research Assistant at the Center for Computational & Data Sciences (CCDS), Independent University, Bangladesh. I completed my Bachelor’s from the Department of Computer Science and Engineering, Khulna University of Engineering & Technology, Khulna, with a CGPA of 3.73/4.00. I have hands-on experience in both academic research and teaching, gained through roles as a Research Assistant and Teaching Assistant/Lecturer across various institutions.
My research is supervised by Prof. Dr. Amin Ahsan Ali and Prof. Dr. AKM Mahbubur Rahman from CCDS. Currently, my researches and projects focus on Multi-modal learning (LLM based foundation models), Trustworthy ML, Federated Learning and Continual Learning/ Adaptive Learning System. I am fortunate to collaborate with and receive mentorship from Md Mofijul Islam, Aman Chadha, Sajib Mistri, Ankur Sarker (All of them are collaborators of CCDS).
I am actively looking for Fully-funded Graduate (Ph.D / Masters) / Visiting Student Researcher positions in good CS research labs around the globe.
News
| Nov 27, 2025 | Our SloMo-Fast, FedPoisonTTP and pFedBBN are avialable in the arxiv. Please have a look at the papers. |
|---|---|
| Jul 10, 2025 | Reaching 200+ Citations of my research papers. Check in my Google Scholar. |
| May 23, 2025 | Two of our papers BD Open LULC Map and RGC-BENT have been accepted in IEEE International Conference on Image Processing (ICIP-2025). |
| Mar 31, 2025 | Our FedCTTA paper got accepted in IJCNN 2025 |
| Nov 27, 2024 | I am excited to share that 3 of my papers have been accepted for presentation at the 27th International Conference on Computer and Information Technology (ICCIT) 2024. |
| Nov 01, 2024 | I have joined as a Research Assistant at Center for Computational & Data Sciences |
| Mar 11, 2024 | Started an internship at the Center for Computational & Data Sciences |
| Feb 24, 2024 | Successfully defended undergraduate thesis under the supervision of Sk. Imran Hossain |
Selected Publications


Research Areas
Multimodal Learning:
-
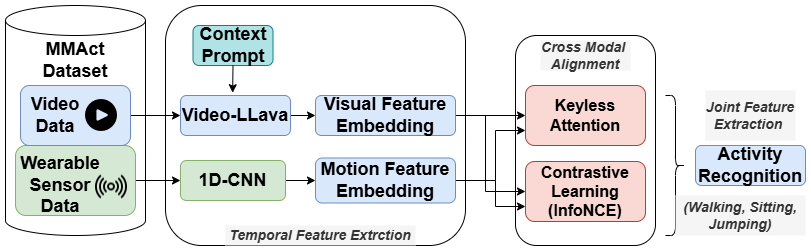 Context-Aware Cross-Modal Alignment for HAR Using LLMs and Wearable Sensors (pdf)
Context-Aware Cross-Modal Alignment for HAR Using LLMs and Wearable Sensors (pdf)A multimodal (video, language, sensor modality) model where video features are obtained from a context prompt guided Video-LLava, and applied Keyless Attention for sensor feature fusion.
-
 Multimodal Bias Removal through Machine Unlearning in Large Language Models (pdf)
Multimodal Bias Removal through Machine Unlearning in Large Language Models (pdf)A multimodal machine-unlearning framework that selectively removes socially biased knowledge from MLLMs while preserving their reasoning ability and overall utility.
-
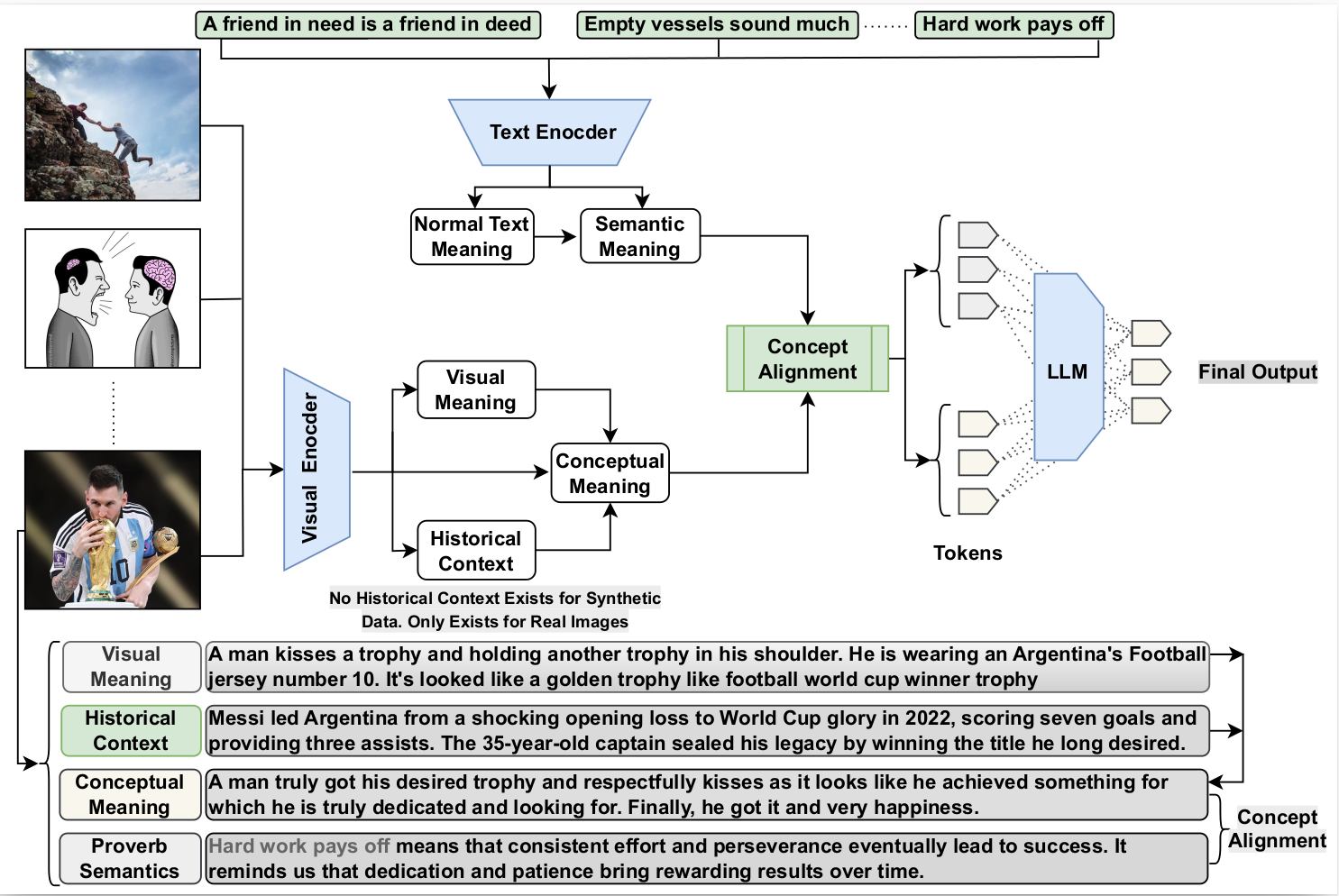 ProverbBench: A Visual Proverbs Benchmark for Evaluating Multimodal Large Language Models (pdf)
ProverbBench: A Visual Proverbs Benchmark for Evaluating Multimodal Large Language Models (pdf)A multimodal proverb-understanding pipeline where text and visual encoders extract meanings, align concepts, incorporate historical context, and generate an LLM-based final interpretation.
Generative AI:
-
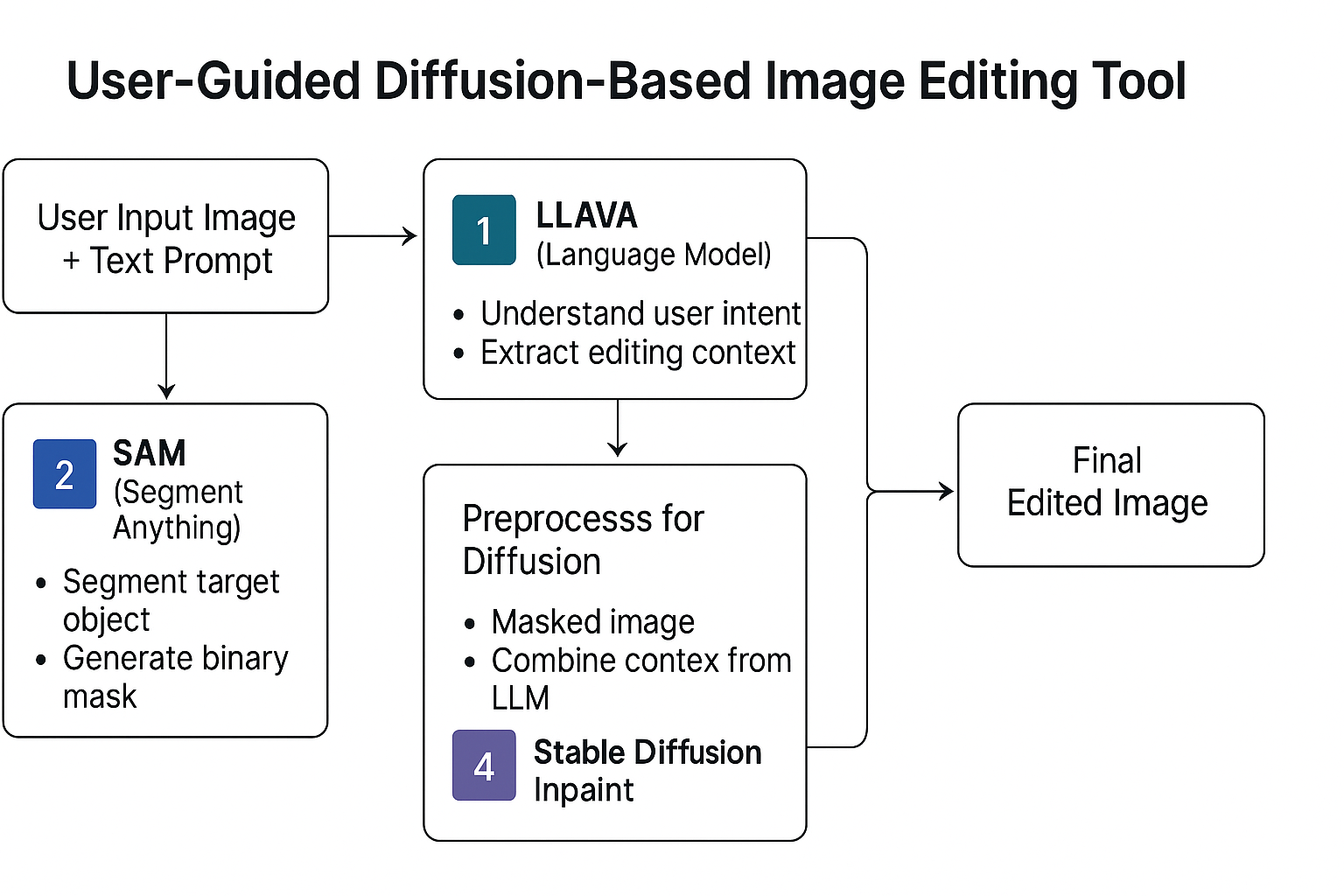 Diffusion-Based Image Editing with Vision-Language Instructions (pdf)
Diffusion-Based Image Editing with Vision-Language Instructions (pdf)An Image Editing Tool with User Instructions had: language processor (LLAVA), segmenter (SAM), and image editor (Stable Diffusion)
Trustworthy ML, Security & Privacy:
-
 A Backpropagation-Free Jailbreak Attacks on Multimodal Large Language Models
A Backpropagation-Free Jailbreak Attacks on Multimodal Large Language ModelsWe introduce a black-box jailbreak framework that leverages reinforcement learning with bandit feedback to attack multimodal LLMs without gradients
- Privacy-Preserving NSFW Image Generation via Diffusion Unlearning
Protecting Diffusion Models (Stable Diffusion, Flux) from NSFW Jailbreaking via Harmful Knowledge Forgetting with Machine Unlearning
- The Dark Side of Prompt Tuning: Poisoning Attacks on Vision-Language Models at Test Time
PGD-based poisoning of unlabeled inference data can corrupt on-the-fly prompt tuning in CLIP-based vision-language models.
- Data Stealing Attacks in Federated Learning for Satellite Communication Systems
Investigated vulnerabilities of federated learning models in satellite communication systems to data stealing attacks (model inversion, membership inference)..
- Federated Unlearning Attack
Designed a black-box attack where a malicious client sends unlearn requests targeting important data of other clients using membership inference attacks.
- Gradient Inversion Attack in Test Time Adaptation (pdf)
Investigates privacy vulnerabilities during model adaptation by recovering input data from gradient signals.
- Federated Adversarial Attack in Test-Time Adaptation
Designed a gradient inversion attack for retrieving local client data during test-time continual learning and Proposed a defence by encrypting gradients before sending to the aggregator.
Federated Learning:
-
 When a Modality is Missing: A Cross-Modal Recovery for Federated Multimodal LLM Models (pdf)
When a Modality is Missing: A Cross-Modal Recovery for Federated Multimodal LLM Models (pdf)Introduces a modality recovery approach for clients missing either image or text in federated multimodal learning.
-
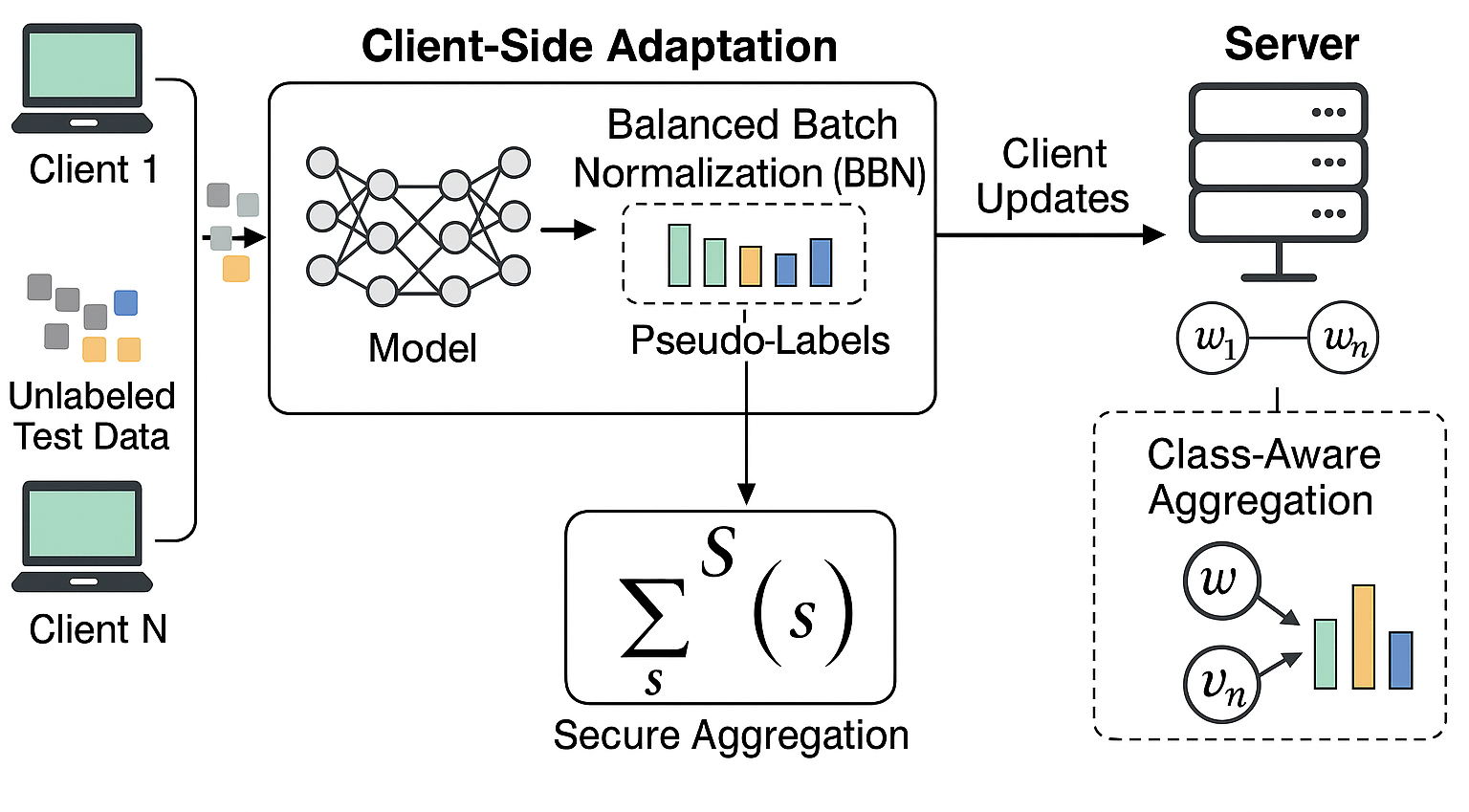 FedBalanceTTA – Federated Learning with Balanced Test Time Adaptation (pdf)
FedBalanceTTA – Federated Learning with Balanced Test Time Adaptation (pdf)Combines test-time adaptation with federated learning to balance performance across domains and clients.
-
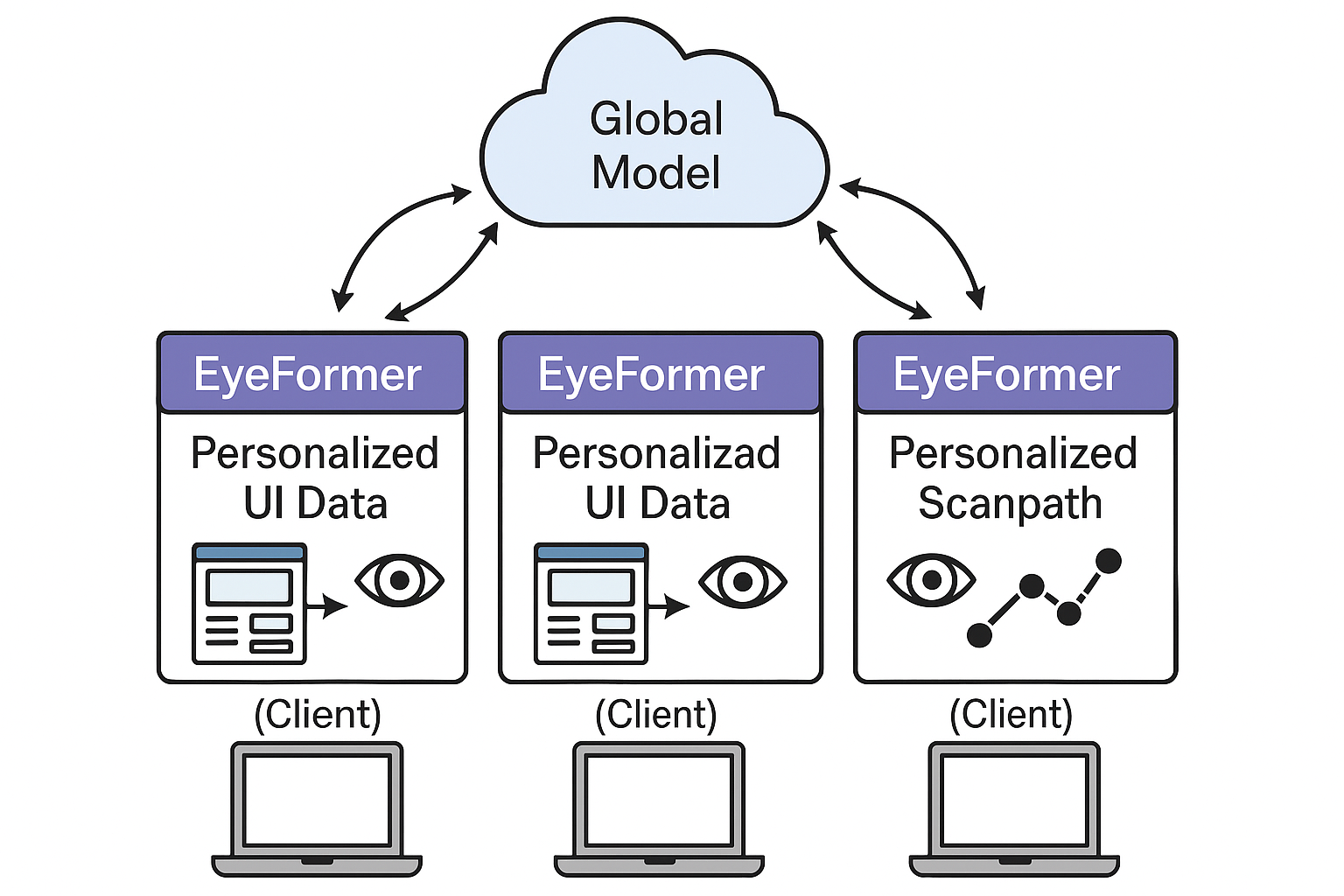 Federated Personalized Scanpath Prediction for Privacy-Preserving UI Optimization (pdf)
Federated Personalized Scanpath Prediction for Privacy-Preserving UI Optimization (pdf)Proposes personalized scanpath learning to optimize user interfaces while preserving eye-tracking privacy.
Human Computer Interaction:
-
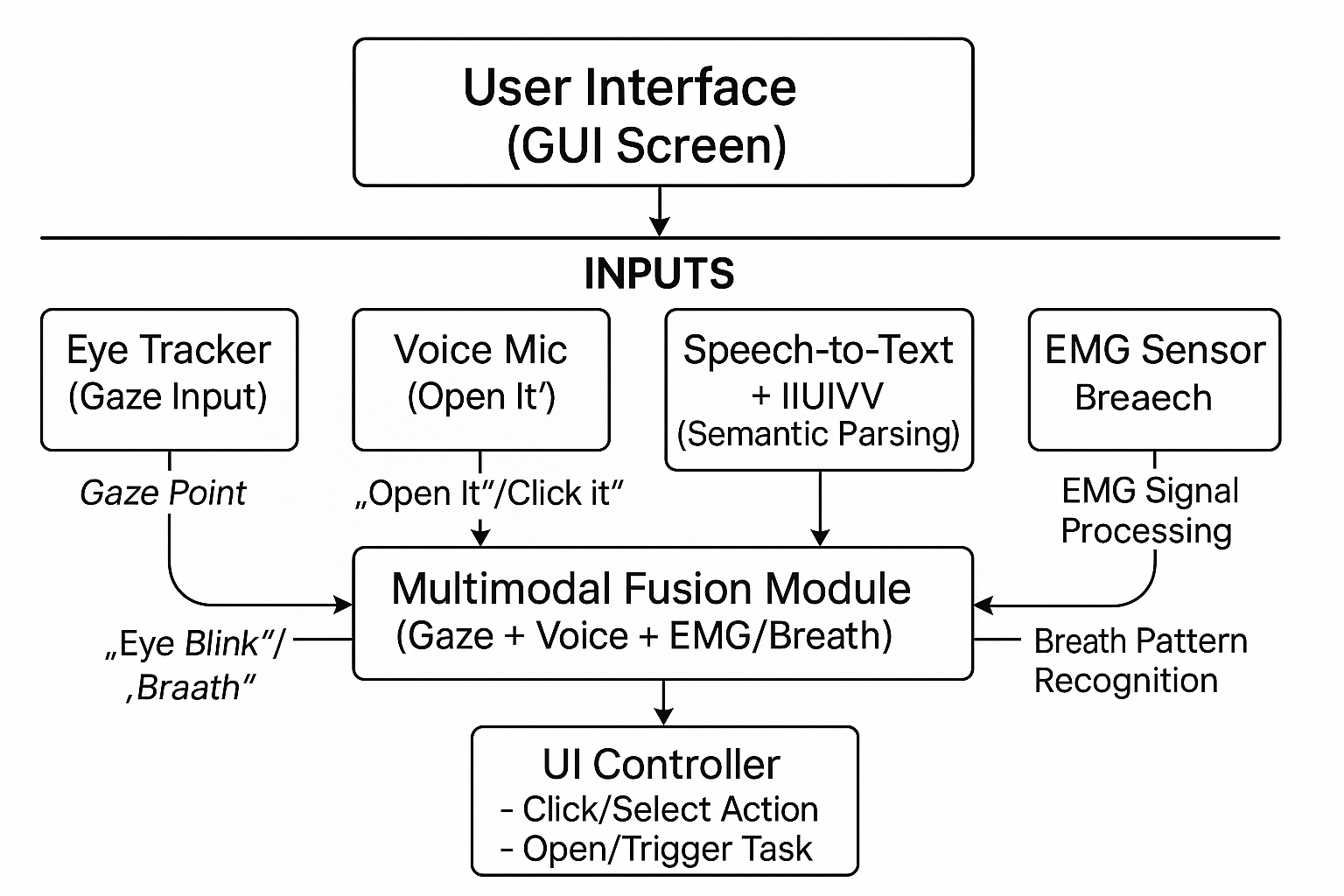 Voice Activated Gaze-Enhanced Multimodal Interaction for Accessibility (pdf)
Voice Activated Gaze-Enhanced Multimodal Interaction for Accessibility (pdf)Combines voice and gaze input to support accessible multimodal interaction for users with limited mobility.
-
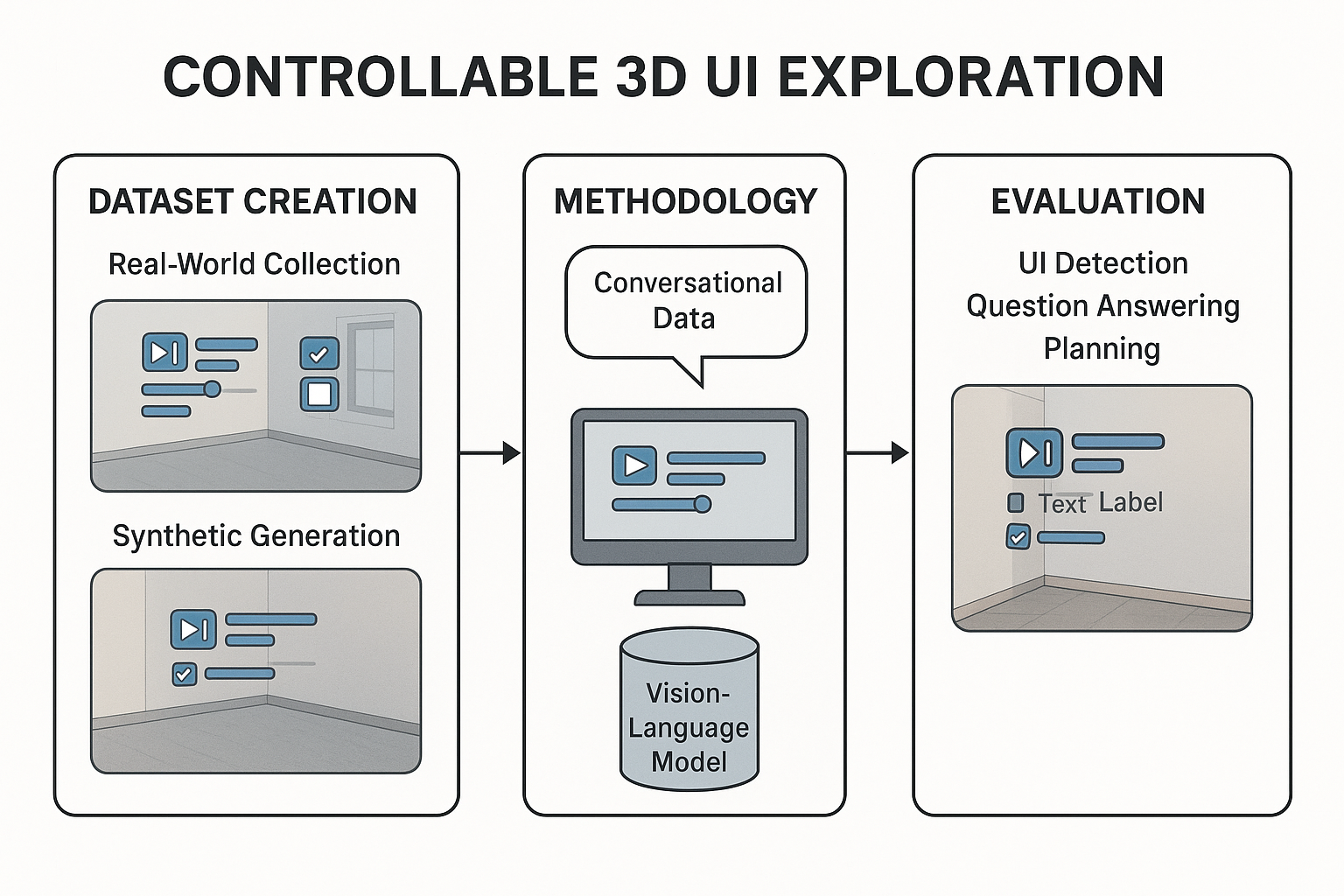 Controllable 3D UI Exploration and its Future (pdf)
Controllable 3D UI Exploration and its Future (pdf)Explores new paradigms for interacting with 3D user interfaces, focusing on control and user experience.
IoT, Embedded System, Wearable/ Wearless Sensor:
- Wearable Sensor Feature Alignment (Accelerometer, Gyro, Orientation) for Human Activity Recognition (pdf)
Aligns sensor features using projection techniques to enhance HAR in low-resource or noisy environments.
Medical Imaging:
- LLM-Driven Question Answering and Captioning for 3D CT and MRI Data (pdf)
A vision encoder to extract feature embedding of 3D brain MRI and abdominal CT volume data and context alignment via question answering and captioning through Large Language Model (LLM/VLM, Qwen-4B)
- Organ-Seg: A Vision-Language and LLM-Enhanced Framework for User-Guided Abdominal Organ Segmentation.
Instruction-guided medical image segmentation framework that combines LLaVA and SAM to deliver accurate, context-aware, and user-driven segmentation, even under false premises.
- 3D Cerebrovascular Segmentation Using Semi-Supervised Approach (pdf)
Semi-Supervised Uncertainty-Aware Knowledge Distillation for brain vessel segmentation from 3D MRA data (ITK-TubeTK dataset)